Văn hóa 'Blameless Post-mortem' tại CLS
1. Mở bài: Nỗi ám ảnh mang tên "Downtime" và tâm lý đổ lỗi
14:00 chiều Thứ Hai – thời điểm lưu lượng truy cập vào hệ thống CLS của một khách hàng tập đoàn lớn đạt đỉnh. Đột ngột, màn hình giám sát tại văn phòng vận hành chuyển sang sắc đỏ rực. Các thông báo CrashLoopBackOff nhảy liên tục trên các pod thuộc cụm Kubernetes (K8s). Toàn bộ nền tảng đào tạo của khách hàng bị tê liệt.
Trong khoảnh khắc nghẹt thở đó, theo bản năng của nhiều tổ chức, câu hỏi đầu tiên vang lên thường là: "Ai là người vừa thực hiện deployment?" hay "Ai đã cấu hình sai file YAML?". Đó là tâm lý tìm kiếm một "người giơ đầu chịu báng" để giải tỏa áp lực tức thời của cấp quản lý và các stakeholders.
Tuy nhiên, tại CLS, chúng tôi chọn một lối đi khác. Thay vì hỏi "Ai?", chúng tôi bắt đầu bằng câu hỏi "Điều gì?": "Điều gì trong hệ thống đã cho phép sự cố này xảy ra?".
Trong môi trường SaaS phức tạp triển khai trên hạ tầng On-premise, việc chỉ trích cá nhân không những không giúp hệ thống ổn định hơn, mà còn là cách nhanh nhất để hủy hoại tinh thần đội ngũ. Khi nhân viên sợ bị trừng phạt, họ sẽ có xu hướng che giấu lỗi lầm, và đó chính là mầm mống cho những thảm họa lớn hơn trong tương lai. Đó là lý do tại sao văn hóa "Blameless Post-mortem" (Phân tích sự cố không đổ lỗi) trở thành "DNA" trong cách vận hành của chúng tôi.
2. "Blameless Post-mortem" là gì và tại sao CLS lại cần nó?
Trong từ điển vận hành của CLS, Blameless Post-mortem không đơn thuần là một buổi họp rút kinh nghiệm. Đó là một quy trình phân tích sự cố mà ở đó, chúng tôi hoàn toàn loại bỏ yếu tố "trừng phạt" ra khỏi phương trình. Mục tiêu duy nhất là: Thấu hiểu toàn diện nguyên nhân và cải thiện hệ thống.
.png)
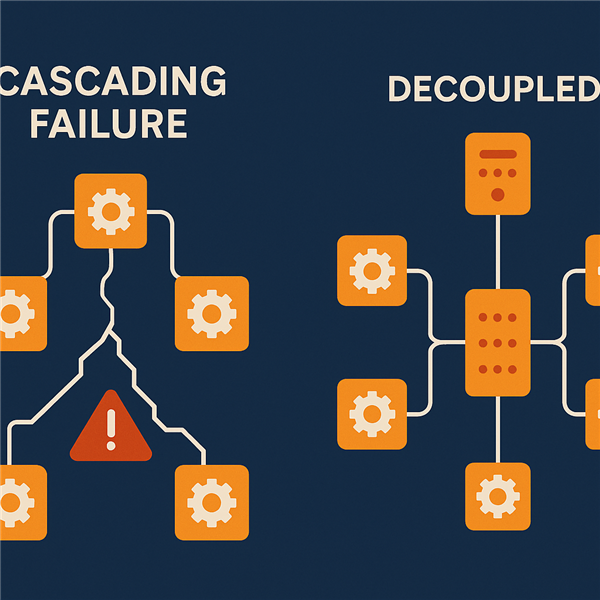
Tại sao chúng tôi lại khắt khe với việc "không đổ lỗi" đến vậy? Câu trả lời nằm ở đặc thù kỹ thuật của Kubernetes On-premise.
Vận hành một hệ thống SaaS trên hạ tầng tự chủ (On-premise) giống như việc lái một con tàu lớn trong vùng biển đầy đá ngầm. Có quá nhiều biến số nằm ngoài tầm kiểm soát tuyệt đối của một cá nhân: từ sự trồi sụt của phần cứng, cấu hình mạng nội bộ phức tạp của khách hàng, cho đến các tương tác chồng chéo giữa các container và node.
Khi một sự cố xảy ra, ví dụ như một deployment làm sập cụm cluster, chúng tôi nhìn nhận rằng:
- Sai sót cá nhân chỉ là bề nổi: Nếu một kỹ sư cấu hình sai, đó là dấu hiệu cho thấy hệ thống thiếu các rào chắn (guardrails) hoặc quy trình kiểm soát (validation) đủ mạnh.
- Hệ thống quá phức tạp để một người chịu trách nhiệm: Trong một môi trường có hàng trăm microservices, lỗi lầm là điều không thể tránh khỏi.
Triết lý tại CLS rất rõ ràng: Chúng tôi mặc định rằng mọi thành viên trong đội ngũ đều có ý định tốt, họ đều là những chuyên gia giỏi nhất và đã nỗ lực hết mình với lượng thông tin họ có tại thời điểm đó. Nếu "thảm họa" vẫn xảy ra, lỗi thuộc về hệ thống, và việc của chúng tôi là cùng nhau "vá" hệ thống đó, chứ không phải "vá" con người.
3. Quy trình thực hiện Post-mortem tại CLS (Thực chiến)
Khi "khói lửa" của sự cố đã tạm lắng và hệ thống đã hoạt động ổn định trở lại, đó là lúc quy trình Post-mortem tại CLS chính thức bắt đầu. Chúng tôi không để những bài học quý giá trôi đi mất theo những dòng log. Thay vào đó, chúng tôi thực hiện một quy trình 3 bước kỷ luật nhưng đầy tính nhân văn:
Bước 1: Tập hợp dữ liệu (The Facts) Trước khi ngồi lại với nhau, chúng tôi cần một bức tranh khách quan, không có chỗ cho sự cảm tính hay những câu "tôi nghĩ là...". Đội ngũ kỹ thuật sẽ cùng nhau khôi phục lại hiện trường thông qua:
- Log & Metrics: Các bản ghi từ hệ thống và các biểu đồ từ dashboard giám sát cho thấy chính xác điều gì đã xảy ra.
- Timeline: Một dòng thời gian chi tiết từ lúc phát hiện cảnh báo đầu tiên, các bước phản ứng của đội ngũ On-call, cho đến khi hệ thống phục hồi hoàn toàn.
Bước 2: Cuộc họp "Blameless" – Nhìn thẳng vào hệ thống Đây là linh hồn của quy trình. Thành phần tham dự không chỉ có Dev hay DevOps, mà còn có sự góp mặt của Product Owner (PO) và đôi khi là đại diện Sales để đánh giá mức độ ảnh hưởng đến cam kết SLA của khách hàng.
Nguyên tắc vàng trong phòng họp: Tập trung vào "Hệ thống" (System), không tập trung vào "Con người" (Person). Chúng tôi sử dụng kỹ thuật "5 Whys" để bóc tách từng lớp vấn đề cho đến khi chạm đến gốc rễ (Root Cause Analysis). Thay vì hỏi "Tại sao anh A lại cấu hình sai?", chúng tôi hỏi "Tại sao quy trình của chúng ta lại cho phép một cấu hình sai được đẩy lên môi trường Production mà không bị chặn lại?".
Bước 3: Hành động khắc phục (Action Items) Mọi cuộc họp Post-mortem tại CLS đều phải kết thúc bằng những con số và đầu việc cụ thể. Những "lỗ hổng" hệ thống được tìm thấy sẽ ngay lập tức được chuyển hóa thành các task trên Jira. Đó có thể là việc tối ưu lại code, bổ sung automated test, hay điều chỉnh cấu hình Auto-scaling trên cụm K8s. Chúng tôi không sửa sai bằng lời hứa "lần sau sẽ cẩn thận hơn", chúng tôi sửa sai bằng cách cải thiện quy trình vận hành.
4. Những rào cản khi xây dựng văn hóa "Không đổ lỗi"
Lý thuyết về "Blameless Post-mortem" nghe có vẻ rất lý tưởng trên giấy tờ, nhưng khi bước vào thực tế vận hành tại CLS, chúng tôi đã vấp phải không ít "tảng đá" ngầm. Để duy trì được văn hóa này, đội ngũ lãnh đạo và kỹ thuật đã phải cùng nhau vượt qua những rào cản tâm lý rất lớn.
.png)
Cái tôi (Ego) của các Stakeholders Thử tưởng tượng: Hệ thống của một khách hàng lớn sập hoàn toàn trong 30 phút, gây thiệt hại về uy tín và doanh thu. Trong những tình huống "nước sôi lửa bỏng" như vậy, bản năng của các nhà quản lý thường là tìm một ai đó để chịu trách nhiệm. Áp lực "Phải có người bị kỷ luật để làm gương" là một rào cản cực lớn.
Tại CLS, chúng tôi phải đấu tranh để thay đổi tư duy này. Chúng tôi thuyết phục các cấp quản lý rằng: Việc trừng phạt một kỹ sư giỏi không làm hệ thống chạy tốt hơn vào ngày mai. Ngược lại, nó sẽ tạo ra một bầu không khí sợ hãi, nơi mọi người chỉ lo bảo vệ bản thân thay vì bảo vệ hệ thống.
Sự nhầm lẫn giữa "Blameless" và "Accountability" Một hiểu lầm phổ biến mà chúng tôi thường gặp là: "Nếu không đổ lỗi, chẳng lẽ làm sai cũng không sao?".
Chúng tôi cần làm rõ: Blameless (Không đổ lỗi) không đồng nghĩa với việc thiếu trách nhiệm. * Đổ lỗi (Blame) là nhắm vào con người, dùng hình phạt để kết thúc sự việc.
- Trách nhiệm (Accountability) tại CLS nằm ở việc mỗi thành viên phải cam kết thực hiện triệt để các Action Items sau sự cố. Nếu bạn mắc lỗi, chúng tôi không phạt bạn. Nhưng nếu bạn đã xác định được giải pháp khắc phục mà không thực hiện để lỗi đó lặp lại, đó mới là lúc vấn đề trách nhiệm được đặt ra.
Trách nhiệm ở đây là trách nhiệm với tương lai của hệ thống, chứ không phải là sự hối lỗi về những gì đã qua trong quá khứ.
5. Kết quả: Hệ thống vững chắc hơn từ những vết sẹo
Tại CLS, chúng tôi thường ví mỗi sự cố như một "vết sẹo" trên cơ thể hệ thống. Nhưng thay vì che giấu chúng, chúng tôi tự hào về những vết sẹo đó, bởi chúng là minh chứng cho sự trưởng thành. Sau một thời gian dài kiên trì với văn hóa Blameless Post-mortem, những thay đổi tích cực đã hiện rõ không chỉ trên các biểu đồ kỹ thuật mà còn trong tinh thần đội ngũ.
Các chỉ số biết nói
- MTTR (Mean Time To Recovery) giảm rõ rệt: Khi không còn nỗi lo bị khiển trách, các kỹ sư tập trung 100% trí lực vào việc tìm kiếm giải pháp phục hồi hệ thống nhanh nhất. Sự phối hợp giữa các bộ phận trở nên nhịp nhàng hơn vì không ai phải tốn thời gian cho việc "đổ lỗi qua lại" (finger-pointing).
- Sự tự tin của đội ngũ tăng lên: Các kỹ sư trẻ tại CLS không còn rụt rè khi phải thao tác trên các cụm K8s phức tạp. Họ biết rằng phía sau họ luôn có một quy trình hỗ trợ và một tập thể sẵn sàng cùng họ giải quyết vấn đề nếu có rủi ro xảy ra.
Tác động sâu sắc đến văn hóa doanh nghiệp Điều tuyệt vời nhất không nằm ở những dòng code, mà nằm ở sự chuyển dịch trong tư duy. Việc Knowledge Sharing (Chia sẻ tri thức) diễn ra một cách tự nhiên và cởi mở hơn bao giờ hết.
Một tài liệu Post-mortem được công khai cho toàn công ty không phải là một "bản cáo trạng", mà là một "giáo trình thực tế" vô giá. Khi mọi người không sợ bị phán xét, họ sẵn sàng chia sẻ cả những sai lầm ngớ ngẩn nhất, và chính từ đó, những người khác sẽ không bao giờ mắc lại lỗi tương tự. Đó chính là cách chúng tôi xây dựng một tổ chức có khả năng học hỏi và tự chữa lành (Self-healing) – giống như chính cơ chế của Kubernetes vậy.
GÓC NHÌN CHUYÊN GIA (LESSONS LEARNED)
Hành trình xây dựng văn hóa "không đổ lỗi" tại CLS không phải là một con đường trải đầy hoa hồng, mà là kết quả của sự kiên trì và kỷ luật. Dưới đây là 3 bài học đắt giá mà chúng tôi muốn chia sẻ lại cho những ai đang vận hành những hệ thống phức tạp:
- Bài học 1: "Lỗi con người là điểm bắt đầu của cuộc điều tra, không phải là điểm kết thúc." Nếu một kỹ sư lỡ tay xóa nhầm một namespace quan trọng trên Production, câu hỏi của người quản lý không bao giờ nên dừng lại ở: "Tại sao anh lại bất cẩn thế?". Hãy đào sâu hơn: "Tại sao hệ thống lại cho phép một cá nhân có quyền xóa namespace dễ dàng như vậy mà không có ranh giới bảo mật (guardrails)? Tại sao chúng ta không có cơ chế xác nhận hai bước (two-factor authorization) cho những lệnh nguy hiểm?". Hãy nhớ: Con người là biến số, hệ thống là hằng số.
- Bài học 2: Sự cố không được văn bản hóa (Documentation) là một sự cố sẽ lặp lại. Tại CLS, một buổi Post-mortem chỉ được coi là kết thúc khi tài liệu về nó được hoàn thiện và lưu trữ trong thư viện chung. Documentation chính là tài sản. Nó giúp những kỹ sư mới gia nhập không phải bước lại vào "vũng bùn" của người đi trước, đồng thời giúp tổ chức tích lũy được tri thức vận hành thực tế mà không sách vở nào dạy được.
- Bài học 3: Sự hỗ trợ từ cấp C-level là điều kiện tiên quyết. Văn hóa "Blameless" sẽ chỉ là một lý thuyết suông nếu cấp lãnh đạo cao nhất vẫn giữ tư duy cũ. Nếu CEO vẫn đòi "đuổi việc ai làm sập web" sau một sự cố nghiêm trọng, thì mọi nỗ lực xây dựng sự an toàn tâm lý (Psychological Safety) của đội ngũ kỹ thuật sẽ đổ vỡ. Tại CLS, sự thấu cảm và tin tưởng được truyền tải từ chính ban giám đốc, tạo nên nền tảng vững chắc để mọi cá nhân dám sai, dám sửa và dám lớn mạnh.
Kết bài: Vận hành hệ thống K8s On-premise cho doanh nghiệp là một cuộc chiến dài hơi. Tại CLS, chúng tôi tin rằng sự ổn định của hệ thống SaaS không chỉ nằm ở những dòng code hoàn hảo, mà nó tỷ lệ thuận với mức độ an toàn tâm lý của đội ngũ đứng sau nó. Chúng tôi chọn lớn lên từ những vết sẹo, vì đó là cách bền vững nhất để phục vụ khách hàng.