Case Study CLS: Khi Microservices "nghẽn cổ chai" chỉ vì... câu lệnh SQL
Chúng ta thường nghe nói chuyển đổi sang Microservices và triển khai trên Kubernetes là "chìa khóa vàng" để scale hệ thống vô hạn. Tôi cũng từng nghĩ vậy, cho đến khi thực chiến với CLS (Cloud Learning System) – hệ thống E-learning doanh nghiệp mà team đang vận hành.
Hệ thống của chúng tôi được thiết kế chuẩn chỉ: tách biệt các service, deploy trên cluster Kubernetes mạnh mẽ. Tuy nhiên, khi quy mô dữ liệu bắt đầu phình to với hàng triệu logs bài học và user activity mỗi ngày, "ác mộng" hiệu năng mới thực sự bắt đầu.
1. Triệu chứng bệnh ("The Pain Point")
Mọi chuyện bắt đầu vào một buổi sáng đầu tuần, khi traffic người dùng doanh nghiệp truy cập để học tập tăng cao. Hệ thống giám sát (Monitoring & Alerting) bắt đầu "gào thét":
- Latency tăng đột biến: Các API của
Course-Service(quản lý khóa học) vàReport-Service(báo cáo tiến độ) phản hồi cực chậm. - Database "thở dốc": CPU của cụm Database (SQL Server) thường xuyên chạm ngưỡng 90-100%.
- Trải nghiệm người dùng tệ hại: Học viên nhìn thấy biểu tượng "loading" xoay vòng vô tận khi tải danh sách bài học. HR thì timeout liên tục khi cố gắng xuất báo cáo đào tạo.
Team Dev ban đầu nghi ngờ do thiếu RAM/CPU ở các Pods trên Kubernetes, nhưng dù có scale out số lượng Pods lên gấp đôi, tình hình vẫn không khả quan. Database vẫn là điểm nghẽn (bottleneck) duy nhất.
2. Chẩn đoán: Kẻ thù giấu mặt
Chúng tôi quyết định đào sâu vào Slow Query Log của Database.
Kết quả thật bất ngờ. Thủ phạm làm tê liệt hệ thống không phải là các logic tính toán phức tạp trong code .NET, mà lại là những dòng lệnh SQL trông có vẻ rất "vô hại". Những câu query được viết vội vàng trong giai đoạn MVP (Minimum Viable Product), thiếu Index, hoặc sử dụng các cú pháp "kém sang" đã trở thành quả tạ kéo lùi toàn bộ hệ thống khi dữ liệu lớn dần.
Trong bài viết này, tôi sẽ chia sẻ lại 4 Case Study thực tế mà team CLS đã gặp phải và cách chúng tôi "tune" lại từng câu SQL để cứu nguy cho hiệu năng hệ thống.
Phần 1: Thực Chiến - Những Sai Lầm "Kinh Điển" & Cách Khắc Phục
Dưới đây là 4 tình huống thực tế (Case Study) mà team CLS đã gặp phải. Có thể bạn sẽ thấy bóng dáng dự án của mình trong đó.
Case 1: Cạm bẫy "Tìm kiếm không Index" (The Missing Index)
Tình huống: Chức năng cơ bản nhất của LMS là hiển thị danh sách khóa học. User thường xuyên filter theo Trạng thái (status) và Danh mục (category_id).
Câu lệnh gốc (The Bad):
SELECT * FROM courses
WHERE status = 'active'
AND category_id = 105;
Vấn đề: Bảng courses của chúng tôi có khoảng 500.000 bản ghi. Khi chạy lệnh EXPLAIN, chúng tôi phát hiện Database đang thực hiện Seq Scan (Full Table Scan). Nghĩa là nó phải lật tung cả 500.000 dòng dữ liệu chỉ để tìm ra vài chục khóa học thỏa mãn điều kiện.
- Query Cost: Rất cao (~5000).
- Latency: ~2 giây (quá lâu cho một API list).
.png)
Giải pháp: Chúng tôi tạo một Composite Index (Index phức hợp) cho hai cột này. Lưu ý thứ tự cột trong Index cũng quan trọng dựa trên độ phân tán dữ liệu (cardinality), nhưng cơ bản là cần có Index.
CREATE INDEX idx_courses_cat_status ON courses (category_id, status);
Kết quả: Database chuyển sang dùng Index Scan (hoặc Bitmap Heap Scan). Nó đi thẳng đến vị trí dữ liệu cần tìm trên cây B-Tree.
- Query Cost: Giảm xuống còn ~50.
- Latency: Giảm từ 2s xuống 50ms.
Case 2: Ác mộng "LIKE" với Wildcard (Leading Wildcard)
Tình huống: Admin cần tìm kiếm nhân sự trong hệ thống theo tên hoặc email. Thói quen của User là gõ một từ bất kỳ (ví dụ "nguyen") và mong đợi hệ thống tìm thấy cả "nguyenvanA" lẫn "hoangnguyen".
Câu lệnh gốc (The Bad):
SELECT id, name, email
FROM users
WHERE email LIKE '%nguyen%';
Vấn đề: Dù cột email đã được đánh Index, câu query này vẫn cực chậm. Tại sao? Vì ký tự % đặt ở đầu chuỗi (%nguyen%). Cấu trúc B-Tree Index hoạt động dựa trên việc sắp xếp từ trái qua phải (Left-to-Right). Khi bạn để % ở đầu, Database không thể biết bắt đầu tìm từ đâu, buộc phải scan toàn bộ bảng.
Giải pháp:
- Ngắn hạn: Nếu nghiệp vụ cho phép (thương lượng với Product Owner), chỉ cho phép tìm kiếm bắt đầu bằng ký tự (Prefix Search).
-- Tận dụng được Index SELECT ... FROM users WHERE email LIKE 'nguyen%'; - Dài hạn: Với yêu cầu tìm kiếm tự do, chúng tôi chuyển sang giải pháp Full-Text Search.
- Với PostgreSQL: Sử dụng
TSVectorvàGIN Index. - Nếu dữ liệu quá lớn: Đẩy dữ liệu sang Elasticsearch để chuyên trị việc search text.
- Với PostgreSQL: Sử dụng
Case 3: Vấn đề phân trang (Pagination) "chết người"
Tình huống: Chức năng "Lịch sử học tập" (Learning Logs) có dữ liệu rất lớn. User muốn xem lại các hoạt động cũ.
Câu lệnh gốc (The Bad):
SELECT * FROM learning_logs
ORDER BY created_at DESC
LIMIT 20 OFFSET 100000;
Vấn đề: Nhiều bạn nghĩ OFFSET 100000 nghĩa là Database nhảy cóc qua 100.000 dòng đầu. Sai lầm! Thực tế, Database phải đọc và load 100.020 dòng từ ổ cứng lên RAM, sau đó ném bỏ 100.000 dòng đầu và chỉ lấy 20 dòng cuối. Càng về các trang sau, câu lệnh càng chậm và ngốn CPU kinh khủng.
Giải pháp: Sử dụng kỹ thuật Keyset Pagination (hay còn gọi là Seek Method). Thay vì dùng OFFSET, chúng ta dùng chính dữ liệu của dòng cuối cùng trang trước làm mốc (anchor).
-- Giả sử trang trước kết thúc ở thời điểm '2023-10-25 10:00:00'
SELECT * FROM learning_logs
WHERE created_at < '2023-10-25 10:00:00'
ORDER BY created_at DESC
LIMIT 20;
Kết quả: Tốc độ truy vấn trang 1 hay trang 1.000 đều nhanh như nhau vì Database luôn nhảy đúng vào mốc thời gian nhờ Index của created_at.
Case 4: "Cơn lũ" nộp bài thi (Bulk Insert vs Loop)
Tình huống: Khi 1.000 học viên cùng nộp bài thi trắc nghiệm (mỗi đề 50 câu). Hệ thống phải ghi nhận 50.000 câu trả lời (records) gần như cùng lúc.
Cách xử lý cũ (The Bad): Code xử lý trong vòng lặp (For Loop), mỗi vòng lặp gọi một lệnh Insert.
// Ví dụ giả mã
for (Answer ans : answers) {
repository.save(ans); // Thực thi 1 câu INSERT
}
Hậu quả: 50.000 câu lệnh INSERT dội bom Database. Connection Pool bị cạn kiệt (exhausted), gây lỗi dây chuyền sang các service khác.
Giải pháp: Chuyển sang Bulk Insert (Batch Insert). Gom 50 câu trả lời của một user thành 1 câu lệnh SQL duy nhất.
INSERT INTO user_answers (user_id, exam_id, question_id, selected_option)
VALUES
(101, 88, 5001, 'A'),
(101, 88, 5023, 'C'),
-- ... 48 dòng khác ...
(101, 88, 5045, 'B');
Kết quả:
- Số lượng Round-trip (giao tiếp mạng) giữa App và DB giảm 50 lần.
- Database xử lý 1 Transaction lớn nhanh hơn nhiều so với 50 Transaction nhỏ.
- Hệ thống chạy mượt mà kể cả khi user nộp bài dồn dập.
Phần 2: Chiến thuật nâng cao – Khi SQL Tuning là chưa đủ
Sửa câu lệnh SQL là bước đầu tiên và hiệu quả nhất, nhưng với một hệ thống Microservices quy mô lớn như CLS, đôi khi Database vẫn bị quá tải dù query đã tối ưu. Lúc này, chúng ta cần những giải pháp ở tầng kiến trúc.
1. Chiến thuật "Chia để trị": Read/Write Splitting
Trong hệ thống CLS, chúng tôi nhận thấy đặc thù của Report Service (xuất báo cáo) là các câu query rất nặng, quét nhiều dữ liệu, nhưng lại không yêu cầu tính "real-time" tuyệt đối (chấp nhận trễ vài giây). Ngược lại, việc User nộp bài thi (Write) cần sự ổn định cao nhất.
Giải pháp: Chúng tôi triển khai mô hình Primary-Replica (Master-Slave):
- Primary Node: Chỉ phục vụ các thao tác GHI (INSERT/UPDATE/DELETE) và các thao tác đọc quan trọng (như check login).
- Read Replica: Phục vụ toàn bộ các thao tác ĐỌC nặng nề từ Report Service.
Điều này giúp luồng báo cáo của HR dù có nặng đến đâu cũng không bao giờ làm "tắc nghẽn" luồng thi cử của học viên.
2. Caching: "Đừng hỏi Database những câu cũ rích"
Có những dữ liệu rất ít khi thay đổi nhưng lại được query liên tục, ví dụ: Danh mục khóa học, Cấu hình hệ thống, Menu phân quyền.
Thay vì mỗi lần User load trang là một lần gọi xuống Database, chúng tôi sử dụng Redis để cache lại các kết quả này.
- Chiến lược: Cache-Aside hoặc Read-Through.
- Lợi ích: Giảm tải được khoảng 30-40% lượng query
SELECTđơn giản nhưng tần suất cao, giải phóng CPU cho Database làm việc quan trọng hơn.
3. Denormalization: Phi chuẩn hóa (Một cách cẩn trọng)
Dân kỹ thuật chúng ta thường được dạy phải tuân thủ chuẩn hóa dữ liệu (Normal Form) để tránh dư thừa. Tuy nhiên, khi làm báo cáo tổng hợp (Dashboard), việc JOIN 5-7 bảng lớn với nhau là ác mộng về hiệu năng.
Giải pháp: Chúng tôi chấp nhận Phi chuẩn hóa (Denormalization) cho một số luồng báo cáo.
- Tạo các Bảng tổng hợp (Summary Tables). Ví dụ: Thay vì tính điểm trung bình mỗi lần xem báo cáo, chúng tôi tính toán sẵn và lưu vào bảng
user_course_summaryngay khi user nộp bài xong. - Khi cần báo cáo, chỉ cần
SELECTtừ bảng summary này, cực nhanh và không cần JOIN.
Phần 3: Kết luận & Takeaways
Quá trình tối ưu hệ thống CLS không diễn ra trong một đêm, nhưng kết quả mang lại là sự ổn định tuyệt vời cho trải nghiệm người dùng. Từ case study này, tôi muốn gửi gắm vài điều tới các bạn Developer và Tech Lead:
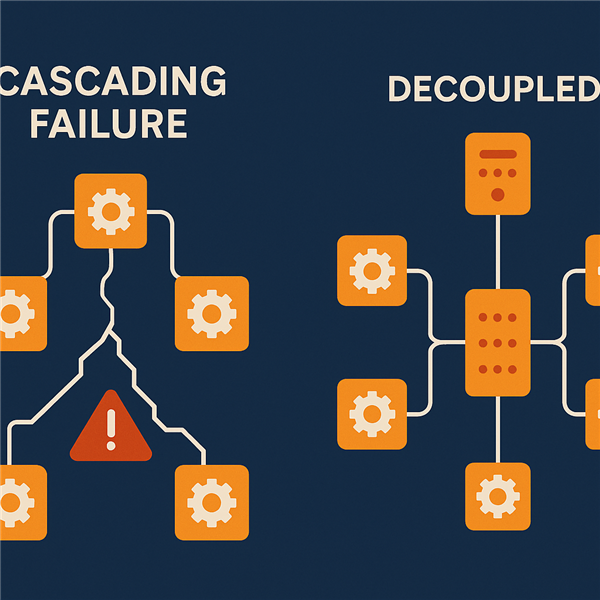
1. Hiệu ứng Domino trong Microservices
Đừng nghĩ rằng "Service của tôi chậm một chút cũng không sao". Trong kiến trúc Microservices, một query chậm gây lock Database có thể làm timeout connection pool, khiến các Service khác (dù không liên quan) cũng chết theo (Cascading Failure).
2. Checklist trước khi Deploy
Đừng bao giờ merge code liên quan đến Database mà chưa tích vào checklist này:
- Đã chạy
EXPLAIN(hoặcEXPLAIN ANALYZE) để xem Query Plan chưa? - Có Index nào bị thiếu (Missing Index) hoặc bị thừa (Unused Index) không?
- Đã test với volume dữ liệu giả lập tương đương Production chưa? (Query chạy nhanh với 10 dòng không có nghĩa sẽ nhanh với 1 triệu dòng).
3. Lời khuyên cuối cùng
Hãy bắt đầu ngay hôm nay bằng việc kiểm tra Slow Query Log của dự án bạn đang làm. Có thể bạn sẽ tìm thấy những "kho báu" hiệu năng đang chờ được khai phá đấy.
Happy Coding & Tuning!